

Introduction
In order to address the attribute-independence problem of the popular naive Bayes classifier, average one-dependence estimators (AODE) algorithm was developed. With very little increase in computational capabilities, it develops classifiers that are accurate than naive Bayes.
Table of contents
Definition
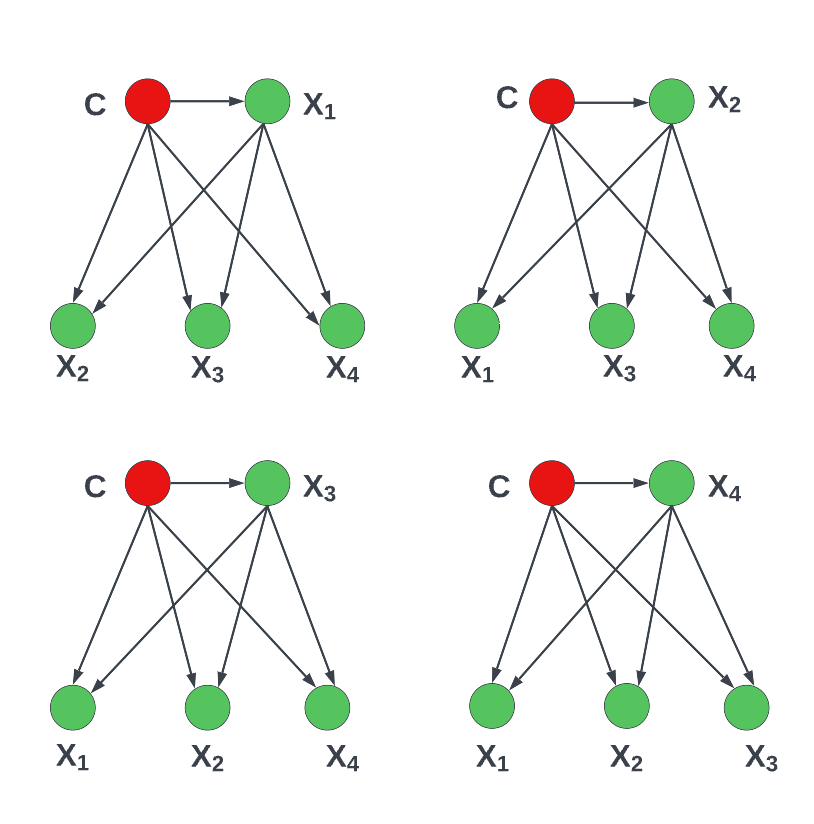
Averaged One-Dependence Estimators is a classification learning technique that forms an ensemble of a specific form of Bayesian network classifier called a n-dependence (in this case 1-dependence) classifier. Each n-dependence (in this case 1-dependence) classifier makes a weaker attribute in-dependence assumption than naive Bayes, allowing each attribute to depend on the class and one common non-class attribute. AODE works on classification by aggregation of all 1-dependence classifier predictions where all attributes are dependent on the single parent as well as the class as long as the minimum frequency constraint.
What are Averaged One-Dependence Estimators
The averaged one-dependence estimators or AODE algorithm is a probabilistic classification learning technique similar to the Naïve Bayes classifier. It was developed to address the attribute-independence problem that befalls the Naïve Bayes classifier. It allows for mutual dependence between pairs of values within each feature vector, but ignores further complex relationships involving three or more features. The algorithm relaxes the ‘naivety’ of the Naïve Bayes classifier and it frequently outperforms Naïve Bayes at the cost of increased computational power.
AODE performs best with a large number of features. However, there is a limit as it examines feature relationships in a combinatorial fashion, it is usually not feasible to use AODE with many data values as that results in high-dimensional vectors that quickly eat up available computational memory. To handle many input values, it is advised to trim the features to only include dependent features where it is known or suspected that those features have a relationship.

Furthermore, it is also possible to add weights to specific averaged one-dependence estimators features. This method is known as WAODE, where the ‘W’ stands for weighted, and it has been shown to yield significantly better results than simple AODE.
Also Read: What is Argmax in Machine Learning?
Classification with AODE
AODE is a better approach to address the infringement of naive Bayes dependence assumption of one attribute to be dependent on the other non-class attributes. To keep up the performance and efficiency it may be desirable to use TAN (1-dependence classifier) where dependence is mapped to one other attribute or class. Most other approaches working with 1-dependence classifiers can cause substantial computational overheads and increases the probability of variance relative to Naive Bayes.
By averaging the predictions of 1-dependence classifiers, AODE avoids model selection. A SuperParent attribute is used to select the parent attribute for every 1-dependence classifier. This type 2 of 1-dependence classifier is called a SuperParent 1-dependence classifier.
Since it makes a weaker assumption of conditional independence than naive Bayes, the AODE algorithm does not require model selection, but has significantly lower bias and a very small increase in variance as compared with naive Bayes.
According to studies, it often has significantly lower zero-one losses than naive Bayes when the time complexity is moderate. AODE was statistically significantly better than many other semi-naive Bayesian algorithms in those studies with the exception of LBR and SP-TAN, with regard to zero-one losses.
In comparison to SP-TAN and LBR, this algorithm achieves lower zero-one losses more often than the reverse, while also having a significantly lower training time complexity compared to SP-TAN and a significantly lower test time complexity compared to LBR.
According to a study, AODE was found to provide classification accuracy that was comparable to that of boosted decision trees, the state-of-the-art discriminative algorithm. When a new instance is available, like naive Bayes, AODE only has to update the probability estimates of the new instance. The AODE algorithm is therefore a good choice for incremental learning, because it features a number of desirable properties which make it a valuable alternative to naive Bayes for a wide range of classification tasks.
Breaking down the Math behind AODE
As explained above, AODE seeks to estimate the probability of each class y given a specified set of features x1, … xn, P(y | x1, … xn). To do so it uses the formula below:
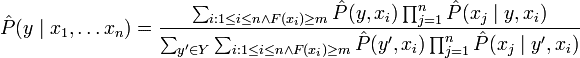
In the formula (*) represents an estimate of P(*) similar to Naïve Bayes’ classification. The difference is in the specified F(xi), which is the frequency the argument appears in the sample data, and m, which is a user specified minimum frequency that an independent variable value must appear in order to be used in the outer summation. For the AODE this m is usually set at 1.
Like naive Bayes, AODE does not perform model selection and does not use tune-able hyperparameters. As a result, it has low variance. It also supports incremental learning whereby the classifier can be updated efficiently with information from new examples as they become available. The formula predicts class probabilities rather than simply predicting a single class, allowing the user to determine the confidence threshold with which each classification can be made. Additionally, it is not limited by missing data as the probabilistic model has a work around which we will not cover in this article, but more information can be found in the following reference Averaged-One-Dependence-Estimators and Missingness.
Also Read: What is Deep Learning? Is it the Same as AI?
AODE Algorithm in Python
Unfortunately, the algorithm is relatively new and does not have an easy to implement build from pre-existing frameworks, like Sklearn. Regardless, using the formula above we can build the appropriate functions to calculate the prior probabilities and obtain the values for the numerator and denominator.
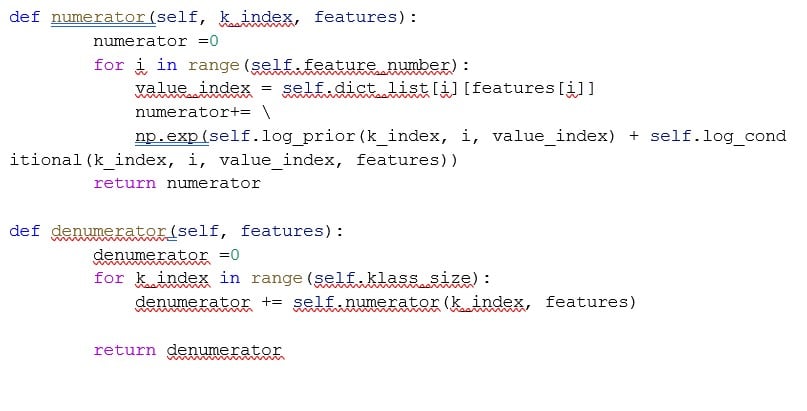
First, let us create the AODE algorithm Class object, which will initialize with the list of independent variables. It will count the number of values for each feature and create zero arrays to later track pairwise feature relationships.

Next, we set up the calculations for the prior probabilities and the conditional probabilities as we do with the Naïve Bayes’ approach. However, we have a restriction on our summation to go out to different frequencies for each sample feature.

Finally, we create helper functions for the numerator and denominator sections, then based on the probability thresholds we select for class identification we can make predictions from the trained algorithm.
Generalizations
After AODE was developed, it has been generalized to Average N Dependence Estimators (ANDE). In this generalization, an ensemble of models is learned, in which each model is a Bayesian Network Classifier that is based on a set of n selected parent attributes in addition to the class. As the value of n increases, bias decreases, thus providing an option for tuning the bias-variance trade-off based on the size of the training set.
Conclusion
The Averaged One-Dependence Estimators (AODE) algorithm emerges as a noteworthy improvement over the traditional Naive Bayes classifier in the machine learning landscape. By addressing the restrictive assumption of feature independence that is intrinsic to the Naive Bayes model, AODE has demonstrated increased accuracy and reliability in various classification tasks. The algorithm’s central premise of considering an average of One-Dependence Estimators enables it to capture relationships between features, resulting in more sophisticated modeling and generalization capabilities.
It’s crucial to be mindful of the increased computational demands AODE may impose due to its more complex structure compared to Naive Bayes. As machine learning continues to evolve and be applied in increasingly intricate domains, the AODE algorithm will likely find its place in the toolset of practitioners looking for a trade-off between performance and computational efficiency, especially in scenarios where capturing inter-feature relationships is important.
References
Lamontagne, Luc, and Mario Marchand. Advances in Artificial Intelligence: 19th Conference of the Canadian Society for Computational Studies of Intelligence, Canadian AI 2006, Quebec City, Quebec, Canada, June 7-9, Proceedings. Springer, 2006.
Perner, Petra. Machine Learning and Data Mining in Pattern Recognition: 13th International Conference, MLDM 2017, New York, NY, USA, July 15-20, 2017, Proceedings. Springer, 2017.
Sammut, Claude, and Geoffrey I. Webb. Encyclopedia of Machine Learning. Springer Science & Business Media, 2011.





