

Introduction to Batch Normalization
Training machine learning & deep neural networks is a complex task that requires overcoming several challenges, including slow convergence and overfitting. These issues have been the focus of extensive research in the field of deep learning, leading to the development of techniques to accelerate the training process and improve model performance.
One such technique that has gained significant popularity in recent years is batch normalization. Batch normalization is a powerful technique for standardizing the inputs to layers in a neural network, which addresses the issue of internal covariate shifts that can arise in deep neural networks.
With batch normalization, it is possible to train deep networks with over 100 layers while consistently accelerating the convergence of the model. Additionally, batch normalization provides inherent regularization, which helps to prevent overfitting. In this article, we will explore the workings of batch normalization, its advantages, and its application to deep networks such as Convolutional Neural Networks. Additionally, we will discuss the role of parameter initialization, normalizer parameters (beta and output), and weight initialization scale in enhancing neural network learning. A smoother parameter space and careful parameter initialization can further optimize the learning process.
Also Read: How to Use Argmax in LaTeX

What is Batch Normalization?
Batch normalization was introduced in 2015, by Sergey Ioffe and Christian Szegedy, in the paper ‘Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift‘. They aimed to speed up deep network training by mitigating the internal covariate shift. This shift represents a challenging situation that arises when the input distribution for each layer experiences changes during the training phase, complicating the network’s training. As a normalization method, batch normalization standardizes the input for every layer so that it has a zero mean and a unit variance.
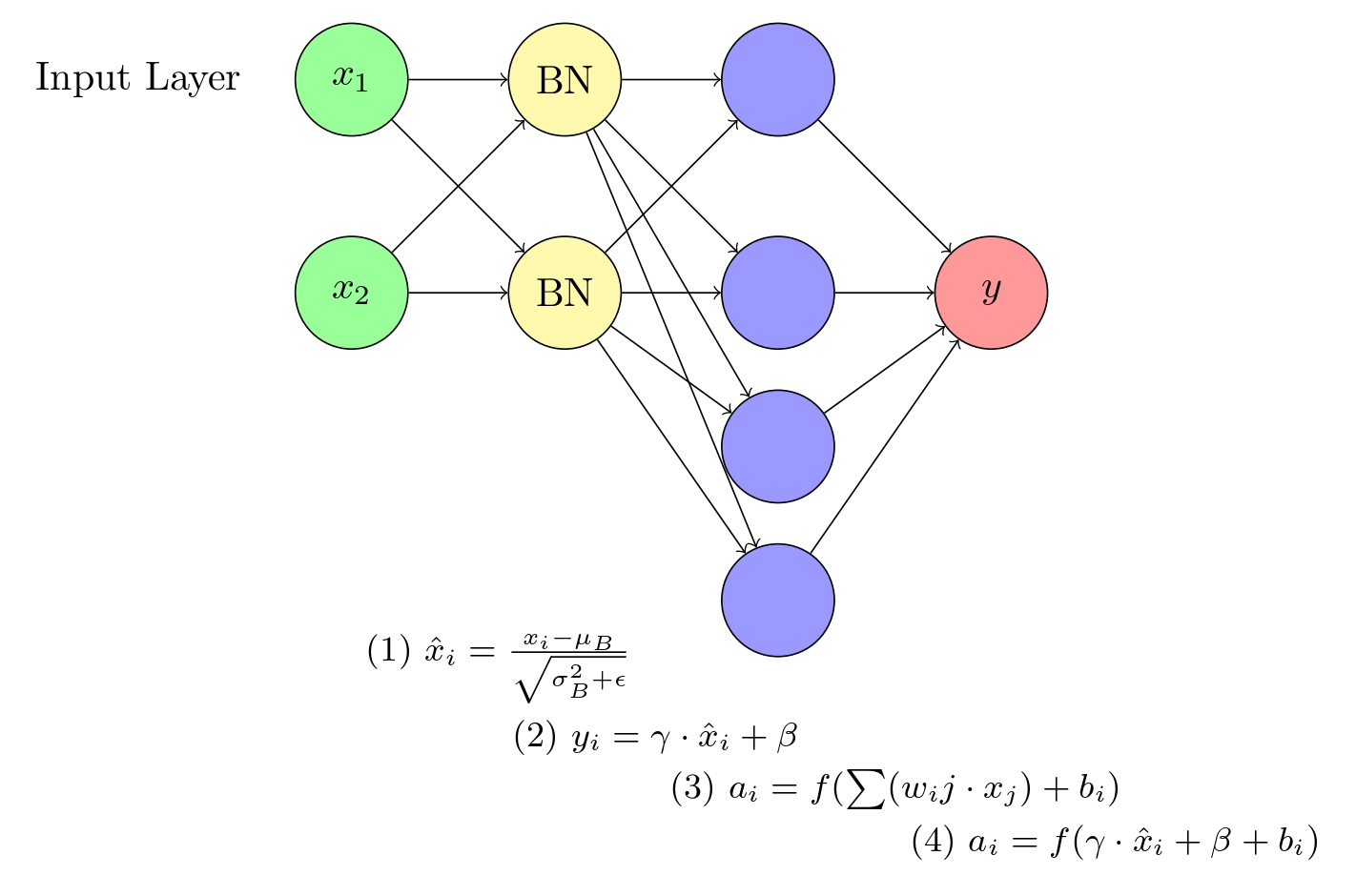
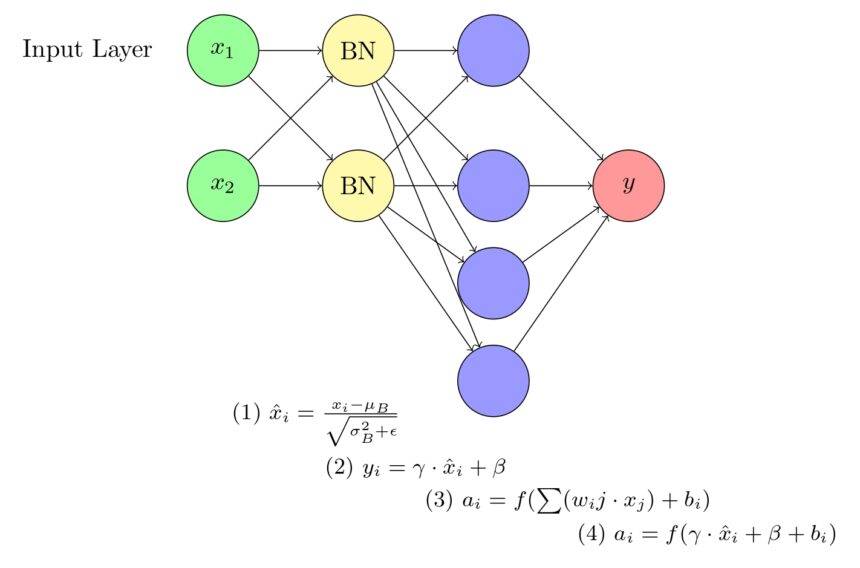
A visual representation of a neural network incorporating Batch Normalization (BN). The network consists of an input layer, a hidden layer, and an output layer. The BN layer is positioned between the input and hidden layers, normalizing the input data and improving the overall training efficiency.