

Introduction
Most of the time in machine learning and deep learning we are attempting to create a computational model that can describe something about a dataset it’s given. Data which we think is sufficient to learn how to produced a desired output relating to some task we want the model to do, is given to the model to learn from.
However, people don’t start learning any task from scratch, we continuously utilize things we’ve previously learned for new circumstances. This same concept can be implemented, in part, in machine learning through what we call transfer learning.
What is Transfer Learning?
Transfer learning is a machine learning technique where a model trained on one task is reused as the starting point for a model on a second task. The idea is to use the knowledge gained from solving one problem and apply it to a related problem, hoping to speed up the solution and reduce the amount of training data needed.
This approach can be especially useful in situations where collecting and annotating large amounts of data for the new task is infeasible, or when the amount of training data available for the new task is small. In these cases, transfer learning can provide a better solution by leveraging the knowledge gained from the previous task.

Transfer learning has been applied in many domains, such as computer vision, natural language processing, and speech recognition, to name a few. It has been shown to be effective in improving the performance of models on a wide range of tasks. There is some support from psychologist C. H. Judd that transfer learning is supported in human learning through generalization of experience [Federica, D.].
The general method of transfer learning is training a model on one set of data and then utilizing the weights and/or feature maps as a starting point for learning on a similar but different dataset. Thus, transfer learning occurs from a source dataset to a target dataset.
Also Read: What is Deep Learning? Is it the Same as AI?
Understanding Transfer Learning from Human Vision
In computer vision, the idea of transfer learning is easily understandable from a human vision correlate, Gabor filters.Gabor filters are commonly used in computer vision and image processing as a way to extract features from images. These filters are named after the mathematician and physicist Dennis Gabor, who first proposed their use for analyzing signals [Gabor, D.].
Gabor filters can be thought of as a combination of a Gaussian function and a complex sinusoidal wave that are multiplied together. When applied to an image, they produce a set of filtered images, each emphasizing a specific spatial frequency and orientation. These filtered images can then be used as input features for a machine learning model.
In the context of transfer learning, Gabor filters can be used to extract features from images for one task, and these features can then be reused as input to a model trained on a related task. This way, the knowledge gained from the first task can be transferred to the second task, potentially improving the performance of the model on the second task [Zhuang, F.]. The below image compares Gabor filters modeled from human visual cortex to a popular convolutional neural network in computer vision called VGG. [Krizvhevskey, A., Shah, A.]
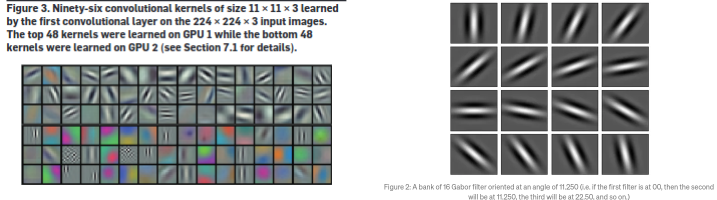
For example, a model trained to recognize faces in images might use Gabor filters to extract features that capture the texture and shape of the faces. These features could then be reused as input to a model trained on a related task, such as recognizing facial expressions. By using the same features, the knowledge gained from recognizing faces can be transferred to recognizing expressions, potentially improving the performance of the model on the second task.
Inductive Transfer Learning
Inductive transfer learning is used in a supervised learning setting, where the model is trained on labeled data for the first task and then fine-tuned on labeled data for the second task.
In inductive transfer learning, the model is typically initialized with pre-trained weights, obtained from solving the first task. The pre-trained weights are then adjusted during training on the second task, allowing the model to learn from the new data and fine-tune its parameters to the new task. This fine-tuning process is typically done using a smaller learning rate compared to training the model from scratch, as the pre-trained weights are already close to a good solution.
Inductive transfer learning has been applied in various domains, such as computer vision, natural language processing, and speech recognition, to name a few. It has been shown to be effective in improving the performance of models on a wide range of tasks, especially when the amount of labeled data available for the new task is small.
Transductive Transfer Learning
Transductive transfer learning differs than inductive that the labels in the target domain are not available or used. The label information is only used in the source domain.
In transductive transfer learning, the model is typically initialized with pre-trained weights, obtained from solving the first task. The pre-trained weights are then used to make predictions on the test data for the second task, and the predictions can then be used to refine the model’s parameters and improve its performance on the second task. This refinement process is done without seeing the true labels for the test data, hence the name transductive transfer learning.
Transductive transfer learning is often used in situations where labeled data is scarce or expensive to obtain, and can be especially useful when the test data for the second task has a similar distribution to the training data for the first task. However, it is important to keep in mind that the performance of transductive transfer learning depends heavily on the quality of the predictions made on the source data, so it may not always provide the best results compared to inductive transfer learning.
Unsupervised Transfer Learning
As we expect, unsupervised transfer learning takes transductive learning a step further in that the label information is not used in either the source or the target data domains. Hence the name “unsupervised”, since all of the learning is done in an unsupervised learning setting.
In unsupervised transfer learning, the model is typically initialized with pre-trained weights, obtained from solving the first task. The pre-trained weights are then used as a starting point for training the model on the second task, where the goal is to learn a good representation of the data that can be used for various downstream tasks, such as clustering or dimensionality reduction.
Unsupervised transfer learning has been applied in various domains, such as computer vision, natural language processing, and speech recognition, to name a few. It has been shown to be effective in improving the performance of models on a wide range of unsupervised tasks, especially when the amount of unlabeled data available for the new task is small. The idea is to leverage the knowledge gained from solving the first task to provide a good initialization for learning the representation of the data for the second task, thus improving the performance of the model.
How to Use Transfer Learning?
Standford’s course in convolutional neural networks for visual recognition provides and a useful and more in-depth discussion on the nuances of using transfer learning. [Fei-Fei, L.] I’ve summarize the gist of the information below.
First, the idea of fine-tuning is to use the weights learned during the source data tasks as the initial weights for the target domain tasks. Else, the source model can be used only as a feature extractor which creates the initial inputs to the target model. The basic idea is to getting started using transfer learning is to first determine whether you need to fine-tune or can just use feature extraction.
The two most important factors to consider are the size of the target dataset and its similarity to the source dataset. Based on these factors, there are four major scenarios and rules of thumb for each one:
- If the new dataset is small and similar to the original dataset, it’s not recommended to fine-tune due to overfitting concerns. The best approach might be (in computer vision) to train a linear classifier on a pre-trained CNN.
- If the target dataset is large and similar to the source dataset, fine-tuning through the full network may be done with more confidence.
- If the target dataset is small but very different from the source dataset, it’s best to only train a linear classifier and it might be better to train the classifier from activations earlier in the network.
- If the target dataset is large and very different from the source dataset, it’s often still beneficial to initialize with weights from a pre-trained model, with enough data and confidence to fine-tune through the entire network.
Once you have determined to what degree you will fine-tune your model, there are some practical considerations.
In transfer learning, it is important to consider the constraints from the pre-trained model when designing the architecture for the target dataset. The pre-trained network may limit the changes that can be made to the architecture, for example, it may not be possible to arbitrarily remove network layers. However, some changes such as running the pre-trained network on images of different spatial size can be easily made. This is because of parameter sharing and the independence of the forward function of feature extracting layers from the input volume spatial size.
It is also important to consider the learning rates used for fine-tuning the model weights and training the new linear classifier. It is common to use a smaller learning rate for the model weights that are being fine-tuned, as compared to the randomly-initialized weights for the new linear classifier. This is because the source model weights are already relatively good, and we do not want to distort them too quickly or too much, especially while the new linear classifier is being trained from random initialization.
Pre-trained Model Approach
In most cases, using a pe-trained model approach is appropriate for fine-tuning to any degree. Here, a source model is trained and saved as a checkpoint which can be used as the initial model weights for the target data and model. Because this approach is so common in computer vision, the Caffe library, Model Zoo, has a community of developers that share their network weights here.
To re-iterate how this approach works, the pre-trained model serves as a general feature extractor that has learned important features from the original dataset. The features extracted by the pre-trained model can be further fine-tuned to improve performance on the new task. The pre-trained model can be fine-tuned through either training the entire network or only the final layers, depending on the size and similarity of the new dataset. This approach has become popular due to the difficulties and computational costs associated with training deep neural networks from scratch.
Examples of Transfer Learning with Deep Learning
Transfer Learning with Image Data

Transfer Learning with Language Data
Although most commonly used in commuter vision tasks, transfer learning can be used on almost any dataset type, including natural language processing. Here, I strongly recommend following the Pytorch Lightning tutorial here which fine-tunes a pre-trained BERT model to adapt to your own datasets easily [Falcon, W.]. This tutorial is a bit more advanced as it requires writing custom data loaders, for those of you who want to get your hands on easy and powerful models for your custom datasets and projects.
Also Read: Computer Vision Technologies in Robotics: State of the Art.
When to Use Transfer Learning?
You should use transfer learning when you want to leverage the knowledge learned from a pre-existing model and apply it to a new, related problem. This is particularly useful when you have limited data for your new problem and can’t train a model from scratch. Transfer learning enables you to use the knowledge gained from a large and diverse dataset, such as ImageNet, to train a new model for a smaller, related dataset, such as a set of medical images. This can lead to improved performance and reduced training time compared to training a model from scratch. Transfer learning is also useful in cases where it is difficult or expensive to obtain labeled data for a new task.
Using transfer learning is often a good approach when starting any new project to test the feasibility of your data and models without having to start from scratch. That means you can quickly get a baseline for how well machine learning or rather, deep learning, can tackler your problem before creating a custom model. This can also be applied on supervised or unsupervised learning models.
Deep Transfer Learning applications
Today, transfer learning is such a widely used practice in deep learning models. Below are just a few examples of the domains in which transfer learning can is already being used.
- Computer Vision: Pretrained models such as VGGNet, ResNet, and Inception can be fine-tuned to classify images into new classes or perform object detection.
- Natural Language Processing: Pretrained language models like BERT, GPT-2, and ELMo can be fine-tuned for various NLP tasks such as sentiment analysis, question answering, and named entity recognition.
- Speech Recognition: Pretrained models for speech recognition such as Deep Speech 2 and WaveNet can be fine-tuned to recognize new accents or languages.
- Recommender Systems: Pretrained deep learning models can be used to initialize models that predict user preferences and make recommendations.
- Healthcare: Pretrained models can be fine-tuned for medical image analysis tasks such as disease classification, segmentation, and diagnosis.
In these applications, transfer learning can significantly reduce the amount of labeled data and computation time required to train a deep learning model, while still achieving high accuracy.