

Introduction
Adversarial Machine Learning (AML) has recently captured the attention of Machine Learning and AI researchers. Why? In recent years, the development of deep learning (DL) has significantly improved the capabilities of machine learning (ML) models in a variety of predictive tasks, such as image recognition and processing unstructured data.
ML/DL models are vulnerable to security threats arising from the adversarial use of AI. Adversarial attacks are now a hot research topic in the deep learning world, and for good reason – they’re as crucial to the field as information security and cryptography. Think of adversarial examples as the viruses and malware of deep learning systems. They pose a real threat that needs to be addressed to keep AI systems safe and reliable.
With the emergence of cutting-edge advances such as ChatGPT’s incredible performance, the stakes are higher than ever regarding the potential risks and consequences of adversary attacks against such important and powerful AI technologies. For instance, it’s been found through various studies that large language models, like OpenAI’s GPT-3, might unintentionally give away private and sensitive details if they come across certain words or phrases. In critical applications like Facial Recognition systems, Self-driving cars, the consequences are severe. So, let’s dive into the world of adversarial machine learning, explore its aspects, and how to protect ourselves from these threats.
What is Adversarial Machine Learning
Adversarial Machine Learning is all about understanding and defending against the attack on AI systems. These attacks involve the manipulation of input data to trick the model into misleading predictions.

Leveraging adversarial machine learning helps enhance security measures and promote responsible AI, making it essential for developing reliable and trustworthy solutions.
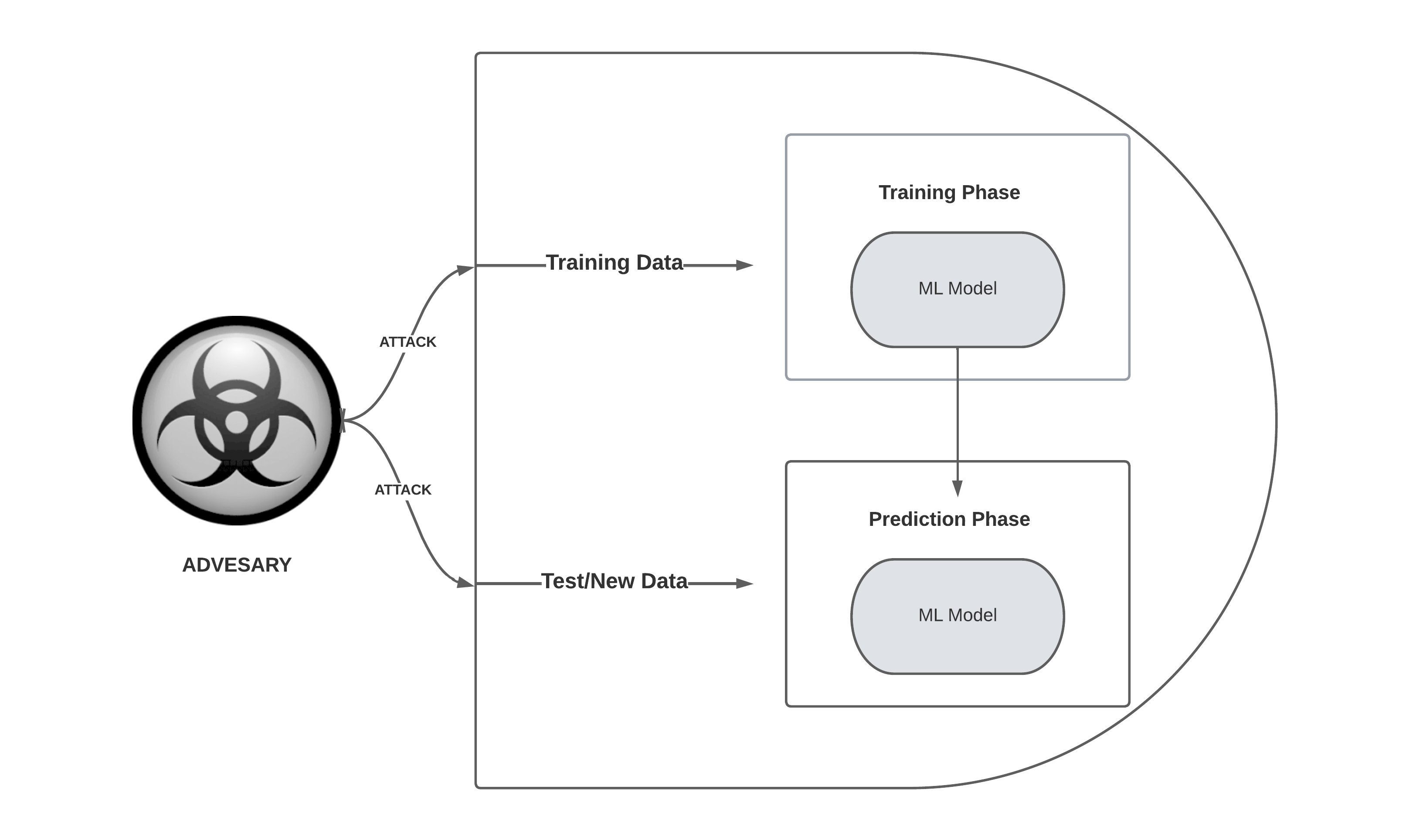
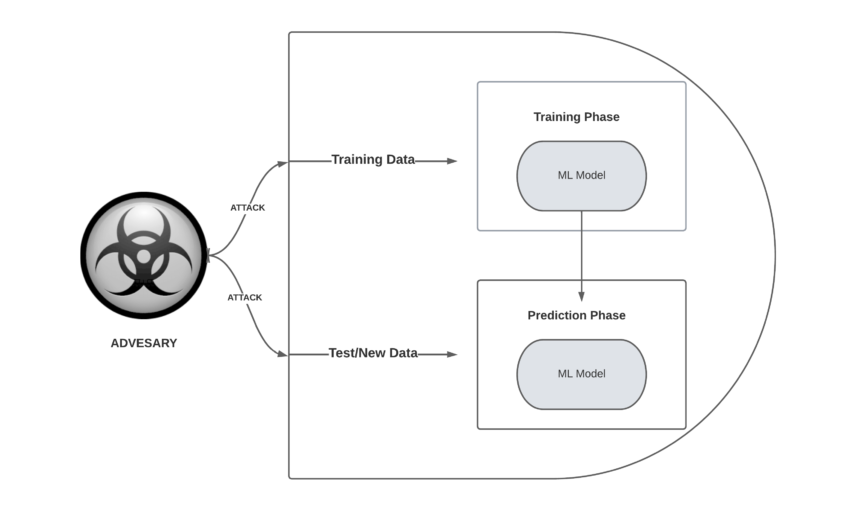
Adversarial attack on a Machine learning model
In the early 2000s, researchers discovered that spammers could trick simple machine learning models like spam filters with evasive tactics. Over time, it became clear that even sophisticated models, including neural networks, are vulnerable to adversary attacks. Although it was recently observed that real-world factors can make these attacks less effective, experts like Nicholas Frosst of Google Brain are still skeptical about new machine learning approaches that mimic human cognition. discussing. Big tech companies have started sharing resources to improve the robustness of their machine learning models and reduce the risk of adversarial attacks.

Source: https://arxiv.org/pdf/1412.6572.pdf
Caption: Adversarial examples causes Neural Network to make unexpected errors by intentionally misleading them with deceptive inputs.
To us humans, these two images look the same, but a Google study in 2015 showed a popular object detection neural network ‘GoogleNet‘ saw the left one as a “panda” and thae right one as a “gibbon” – with even more confidence! The right image, an “adversarial example,” has subtle changes that are invisible to us but completely alter what a machine learning algorithm sees.
Machine learning models, especially deep neural networks (DNNs), have completely dominated the modern digital world, enabling significant advances in a variety of industries through superior pattern recognition and decision-making abilities. However, their complex calculations are often difficult for humans to interpret, making them appear as “black boxes.” Additionally, these networks are susceptible to manipulation through small data alterations, leaving them vulnerable to adversarial attacks.