


Introduction
In recent years, the field of artificial intelligence and machine learning has made tremendous strides, with the development of neural networks playing a key role in this progress. These networks, inspired by the human brain’s neural structure, have the ability to process and learn from vast amounts of data. As their complexity increases, the demand for optimized architectures to enhance efficiency and performance grows. Neural Architecture Search (NAS) addresses this need by automating the design of neural architectures for a range of tasks, often surpassing human-designed alternatives.
Among the most recent notable achievements in AI is ChatGPT, a powerful language model that uses the Transformer architecture to revolutionize natural language understanding. By utilizing NAS techniques, we can optimize Transformer-based models to attain remarkable performance while maintaining resource efficiency. NAS, a crucial aspect of automated machine learning (AutoML), is closely linked to hyperparameter optimization (HPO) and seeks to discover high-performing architectures within specified search spaces, budgets, and datasets.
The growing interest in NAS for Transformers, BERT models, and Vision Transformers across language, speech, and vision tasks highlights the need for Neural Architecture Search methods and a discussion of potential future directions in the field.
Also Read: Glossary of AI Terms

What is Neural Architecture Search?
Neural Architecture Search (NAS) is a process that automates the design of neural network architectures, which are the foundational structures of deep learning models.
The goal of NAS is to find the optimal architecture for a specific task, such as image recognition or natural language processing, by searching through a vast space of possible configurations.
The mentioned configurations include a range of architectural components and parameters like the number of layers, layer types, connections between layers, activation functions, and other hyperparameters.
By doing so, NAS can potentially discover architectures that outperform human experts’ designs.
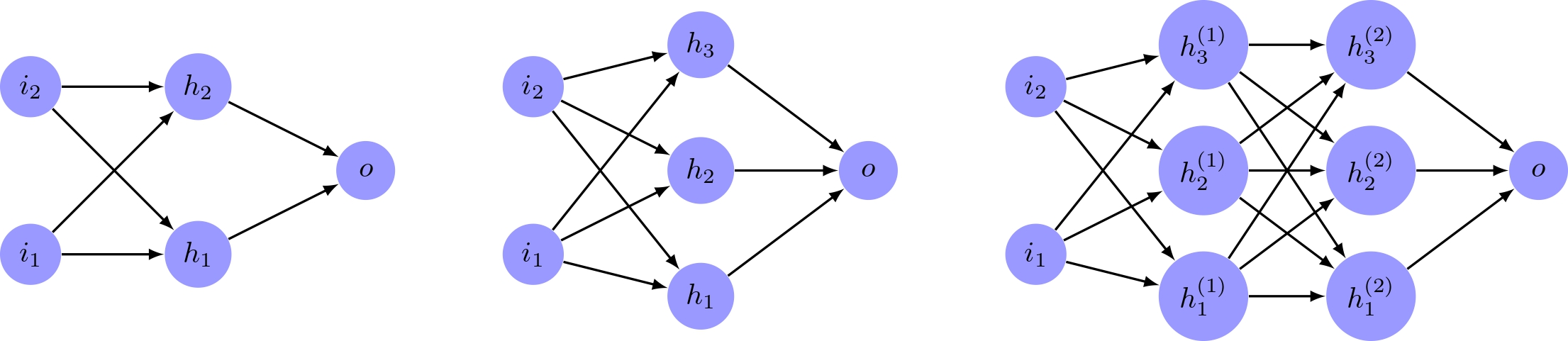
Neural Architecture Search (NAS): Side-by-side comparison of three different neural network architectures (all solving the same problem) with the same input and output nodes but varying hidden layers and nodes.
As shown in the image, the three neural network architectures vary in terms of their hidden layers and nodes, leading to differences in model complexity, computational requirements, and potentially, performance. The NAS process involves searching through various architectures and evaluating their performance on the given task to find the optimal structure that balances accuracy and computational efficiency.
Traditionally, designing neural network architectures has been a labor-intensive and time-consuming process, relying heavily on the expertise of researchers and practitioners. However, NAS leverages advanced optimization techniques like random search, Bayesian optimization, evolutionary algorithms, and reinforcement learning to explore the search space and identify the best neural architectures.
Democratization of Deep Learning
NAS has played a significant role in democratizing deep learning by enabling a wider range of users to develop high-performing models without requiring expert knowledge in the field. This, in turn, has accelerated the adoption of deep learning in various domains, fostering innovation and promoting the development of new applications and services.
Balancing Network Weights is essential for achieving high Validation Accuracy in Convolution Layers, which in turn ensures robust performance in real-world scenarios.
NAS techniques can be broadly categorized into black-box optimization-based techniques and one-shot techniques.
The search space is a critical aspect of NAS. It is the set of all architectures that a NAS algorithm can select. Search spaces can range from a few thousand to over 10^20 in size. Designing a search space involves a trade-off between human bias and the efficiency of the search. Common search space categories include macro search spaces, chain-structured search spaces, cell-based search spaces, and hierarchical search spaces.
Some popular NAS methods include reinforcement learning, evolutionary algorithms, Bayesian optimization, and NAS-specific techniques based on weight sharing. One-shot techniques have emerged as an efficient way to speed up the search process compared to black-box optimization techniques.
NAS has expanded beyond image classification problems to many other domains, such as object detection, semantic segmentation, speech recognition, partial differential equation solving, and natural language processing.
A Brief History of Neural Architecture Search
In its early years, NAS was primarily focused on a toy or small-scale problems, as the computational resources and techniques available at the time were insufficient for addressing more complex tasks. The development of NAS has been marked by several key milestones, including the adoption of evolutionary algorithms and Bayesian optimization methods.
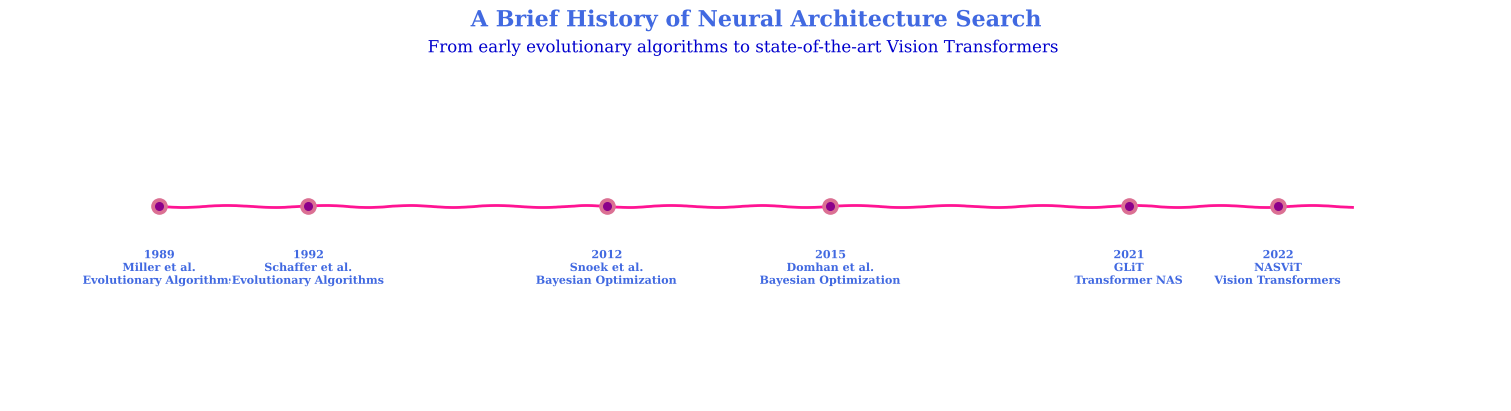
Charting the Evolution of Neural Architecture Search: From the early breakthroughs in evolutionary algorithms to the cutting-edge advancements in Vision Transformers.
Evolutionary algorithms were among the first approaches used in NAS, with pioneering work dating back to the late 1980s and early 1990s. Researchers Verbancsics & Harguess (2013) made significant contributions by employing evolutionary algorithms to optimize neural network architectures. These algorithms relied on the principles of natural selection, mutation, and crossover to iteratively explore the search space of possible architectures, seeking to identify the best-performing candidates.
Bayesian optimization emerged as another powerful technique for NAS in the early 2010s. The works of Snoek et al. (2012) and Domhan et al. (2015) demonstrated the effectiveness of this approach in optimizing neural network architectures. Bayesian optimization leverages probabilistic models to predict the performance of potential architectures, guiding the search process toward more promising candidates. This method allows for more efficient exploration of the search space, reducing the computational burden and making it possible to tackle larger-scale problems.
The success of NAS methods for Convolutional Neural Networks (CNNs) has inspired researchers to explore similar methods for highly successful complex architectures like Transformers and Vision Transformers.
In neural networks Search via Parameter Sharing method has become a popular choice for optimizing network architectures, as it utilizes Stochastic Gradient Descent to minimize the Thousands of GPU hours traditionally required.
This emerging research direction in Natural Language Processing (NLP) and Computer Vision calls for a review of NAS methods specifically tailored to Transformers and their related architectures, with a focus on efficient search spaces and search algorithms.
While numerous survey papers have been published on Transformers, Vision Transformers, AutoML, NAS, and HW-NAS, most emphasize theoretical concepts of search methods and focus more on CNNs than Transformers.
Recently, however, there have been dedicated review papers for Transformer-based architecture search methods. Research papers, such as NASViT, GLiT, and NASformer, provide a comprehensive review of state-of-the-art Neural Architecture Search methods and discuss potential future directions in the field.
NASViT, introduced in 2022, GLiT, published in 2021, and NASformer have all made significant contributions to NAS for Transformers and Vision Transformers by introducing new search spaces, search algorithms, and efficient self-attention mechanisms. These studies demonstrate the potential for better performance and efficiency in image recognition and other vision tasks using the proposed architectures, highlighting the importance of continuing research in this area.
Neural Architecture Search is a complex and computationally intensive process that involves several key components, including the search space, search process, and performance prediction.

Visualizing the Neural Architecture Search Process: An intuitive flowchart depicting the key components and interactions involved in optimizing deep learning models for enhanced performance and efficiency. Source Reference: https://www.automl.org/wp-content/uploads/2018/12/nas-1.pdf
Search Space
The search space refers to the set of all possible neural network architectures that can be generated and explored by Neural Architecture Search. This space can be vast and challenging to navigate due to the numerous hyperparameters and architectural choices, such as the number of layers, types of layers, kernel size, and connectivity patterns.
One of the primary challenges in NAS is dealing with the vast search space of potential architectures.
A smaller search space might result in sub-optimal architectures that underperform, while a larger search space can lead to an explosion in the number of possibilities, making the learning task extremely difficult or even infeasible.
Given that only a tiny fraction of architectures can be explored to train the controller, finding high-performing architectures within a large search space becomes a complex and demanding task.
There are two widely used search space types: (i) Micro/Cell-level Search space and (ii) Macro/Layer-wise Search space. These are applicable to any kind of Neural Network, including Transformers.
The details on specific methods are inspired by the research paper “Neural Architecture Search for Transformers: A Survey“.
Micro/Cell-level Search space
This method involves searching for a small Directed Acyclic Graph (DAG) or a cell structure instead of the entire network end-to-end. The same cell structure is replicated across different layers in the network. Examples of NAS methods using this approach are the Evolved Transformer and DARTS-Conformer.
Macro/Layer-wise Search space
This method offers more flexibility by constructing a chain-type macro-architecture and searching for different operations/configurations at each layer. This approach results in more robust models that can be tailored for hardware-friendly inference and better performance. Methods like GLiT rely on layer-wise search.
With respect to Transformers, there are two categories of search spaces based on the type of operations in the primitive element set: (i) Self-Attention (SA) only search space and (ii) Hybrid Attention-Convolution search space.
Self-Attention (SA) only Search Space
This search space is limited to elements found in Vanilla Transformers, such as head number, FFN hidden size, etc. Early NAS methods like Evolved Transformer and AutoFormer relied on this search space for tasks in language and vision domains. Some examples of SA-only search spaces include AutoFormer, Twins Transformer, and DeiT search spaces.
Hybrid Attention-Convolution Search Space
This category combines the Self-Attention mechanism with Convolution operations (Spatial and Depthwise Convolutions) to leverage the strengths of both. It is used in various applications, including NLP, speech, and vision tasks. Examples include the Convolutional Vision Transformer (CvT) and MobileViT.
The NASViT search space is inspired by the architecture called LeViT, with the first four layers consisting of Convolution operations for efficient high-resolution feature map processing, followed by Multi-Head Self-Attention (MHSA) operations in the remaining part of the network to handle low-resolution embeddings. This hybrid approach allows the model to capture both local and global information effectively.
Search Strategy
The search strategy is the algorithm used to explore the search space and identify the best neural architectures. Some Popular algorithms include random search, Bayesian optimization, evolutionary algorithms, genetic algorithms, and reinforcement learning, each with its strengths and weaknesses. We now will discuss some of these algorithms.
Reinforcement Learning (RL)
Reinforcement learning has also demonstrated success in driving the search process for superior architectures. Early NAS approaches relied on the REINFORCE gradient as the search strategy. Alternative methods such as Prooneximal Policy Optimization (PPO) and Q-Learning have been adopted by Zoph et al. (2018) and Baker et al. (2016), respectively. Notably, Hsu et al. (2018) introduced MONAS, a multi-objective NAS method that optimizes for scalability by considering both validation accuracy and power consumption using a mixed reward function:
R = α * Accuracy – (1 – α) * Energy
Bayesian Optimization
Bayesian optimization has been a critical component in the early development of Neural Architecture Search (NAS) techniques. It optimizes an acquisition function based on a surrogate model, which guides the selection of the next evaluation point in the architecture search space. By modeling the performance of various architectures and intelligently proposing new candidates to be evaluated, Bayesian optimization enables efficient exploration of the search space.
Pioneering applications include Kandasamy et al.’s (2018) NASBOT, which employs a Gaussian process-based approach, and Zhou et al.’s (2019)
By guiding the search model to start the investigation from simple models and gradually evolving towards more complex architectures, it introduces a form of curriculum learning. This approach can improve search efficiency by progressively building upon the knowledge gained from simpler models, which can be used to guide the search toward promising areas of the architecture space. As the search model progresses through this curriculum, it becomes increasingly adept at identifying high-performing architectures, thereby improving the overall efficiency and effectiveness of the NAS process.
One-shot learning
One-shot learning is an alternative approach that has gained popularity in NAS research due to its efficiency in circumventing the computational burden of training each architecture from scratch. Instead of training individual architectures, one-shot learning trains a single hypernetwork or supernetwork, implicitly training all architectures in the search space simultaneously.
A hypernetwork is a neural network that generates the weights of other neural networks, while a supernetwork, often used synonymously with “one-shot model,” is an over-parameterized architecture that contains all possible architectures in the search space as subnetworks.
The scalability and efficiency of supernetworks lie in the fact that a linear increase in the number of candidate operations results in a linear increase in computational costs for training, while the number of subnetworks in the supernetwork increases exponentially. This allows for training an exponential number of architectures at a linear compute cost.
A key assumption in one-shot learning is that the ranking of architectures evaluated using the one-shot model is relatively consistent with the ranking obtained from training them independently. The validity of this assumption has been debated, with evidence both for and against the claim in various settings. The extent to which this assumption holds true depends on the search space design, the techniques used to train the one-shot model, and the dataset itself.
Once a supernetwork is trained, a search strategy must be employed to evaluate architectures. This strategy could involve running a black-box optimization algorithm while the supernetwork is training or after it has been trained. Another popular approach is to use gradient descent to optimize the architecture hyperparameters in tandem with training the supernetwork, as demonstrated by DARTS (Liu et al., 2019b) and subsequent methods.
Performance Estimation Strategy
To evaluate the quality of a candidate architecture, NAS relies on performance predictors, which estimate the model’s performance on the target task without requiring full training. This is crucial for reducing the computational resources needed during the search process.
Low-Fidelity Estimation Methods
Low-fidelity estimation methods aim to accelerate NAS by:
- Employing early-stopping, which uses validation accuracy obtained after training architectures for fewer epochs.
- Training down-scaled models with fewer cells during the search phase.
- Training on a subset of the data.
However, these methods tend to underestimate the true performance of architectures, potentially affecting their relative ranking. This undesirable effect becomes more prominent when the low-fidelity setup is dissimilar to the full training procedure.
Regression-Based Estimation Methods
Another class of performance estimation methods uses regression models to predict final test accuracy based on architecture structure or extrapolate learning curves from the initial training phase. Some examples of regression models explored in the literature include:
- Gaussian processes with tailored kernel functions.
- An ensemble of parametric functions
- Tree-based models
- Bayesian neural networks
- ν-support vector machine regressors (ν-SVR), achieving state-of-the-art performance.
While these methods can often predict performance rankings better than early-stopping counterparts, they require a large amount of fully evaluated architecture data to train the surrogate model and optimize hyperparameters effectively. This high computational cost makes them less favorable for NAS unless the practitioner has already evaluated hundreds of architectures on the target task.
Weight Sharing
Weight sharing, employed in one-shot or Gradient-Based Methods, reduces computational costs by considering all architectures as subnetworks of a supernetwork. The supernetwork’s weights are trained, and the architectures inherit the corresponding weights. However, weight-sharing rankings often correlate poorly with the true performance rankings, leading to sub-optimal architectures when evaluated independently.
Zero-Cost Estimation Methods
Recent work proposes estimating network performance without training by using methods from pruning literature or examining input gradients’ covariance across different input images. While these methods incur near-zero computational costs, their performance is often not competitive and does not generalize well to larger search spaces. Moreover, these methods cannot be improved with additional training budgets.