

Introduction
“Data is the new oil” implies that data is a valuable resource that can drive innovation, growth, and competitive advantage for businesses. Businesses are generating more data than ever before, but they often struggle to tap into the full potential of their data, leaving valuable insights untapped and opportunities unrealized. This can be due to a lack of technical expertise or resources to manage and maintain data systems, as well as siloed data that is difficult to access and integrate.
The process of taking insights or information gleaned from data analysis and using it to drive action or decision-making is called activation. Activation is a critical component of the data lifecycle, enabling businesses to unlock the full potential of their data and drive meaningful outcomes. That is where Reverse ETL comes in. Developers and data engineers have built modern data stacks that make data more accessible to business users and by effectively activating data insights, businesses can stay competitive, drive growth, and improve customer experiences.
Also Read: What is NLP?
What is ETL
ETL was introduced as a process for integrating and loading data for computation and analysis, eventually becoming the primary method to process data for data warehousing projects.

ETL stands for Extract, Transform, and Load. It is a process used to extract data from various sources, transform it into a format suitable for analysis, and load it into a target database or data warehouse. The ETL process is critical for data integration, data warehousing, and business intelligence. It enables organizations to consolidate data from multiple sources, transform it into a consistent format, and load it into a target system where it can be used for analysis and reporting.
ETL processes are often used to create and maintain a single source of truth. By extracting data from multiple sources, transforming it to meet certain standards, and loading it into a single destination system, organizations can ensure that all data is consistent and accurate. Having a single source of truth is important because it helps prevent inconsistencies and errors in data analysis and reporting. If multiple versions of the same data exist in different places, it can lead to confusion, mistakes, and wasted time. By consolidating data into a single source of truth, organizations can improve data quality and make better-informed decisions.
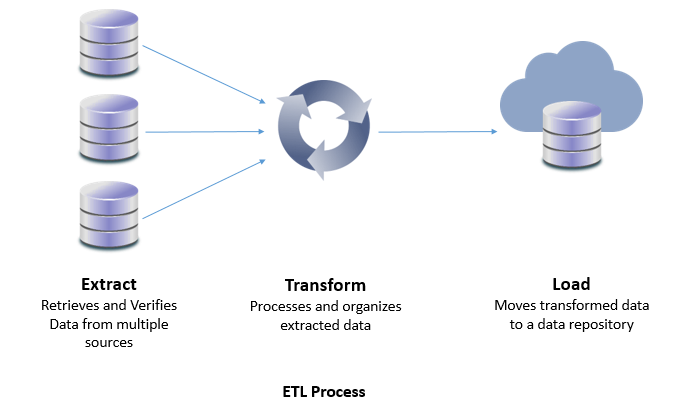
Extract
The first step of the ETL process is to extract data from various sources such as databases, applications, and files. Data can be extracted from different types of sources, including structured, semi-structured, and unstructured data. This step involves connecting to the source system, identifying the data to be extracted, and pulling the data from the source system.
Data extraction can be performed in different ways, such as full extraction, incremental extraction, or delta extraction. Full extraction involves extracting all the data from the source system, while incremental extraction only extracts new or modified data since the last extraction. Delta extraction extracts changes that have occurred since the last extraction, making it a faster and more efficient method of extraction.
Transform
The second step of the ETL process is to transform the extracted data into a format that is suitable for analysis. This step involves cleaning the data, removing duplicates, and converting it into a consistent format. Transformations can be performed in various ways, such as filtering, sorting, aggregating, joining, and splitting data.
Data transformation is critical to ensure data quality, consistency, and accuracy. It also involves data enrichment, where new data is added to existing data to provide more context and insights.
Load
The final step of the ETL process is to load the transformed data into a target database or data warehouse. This step involves mapping the data to the appropriate fields in the target system and ensuring that the data is loaded correctly. The target system can be a relational database, data warehouse, or data lake, depending on the organization’s requirements.
Data loading can be performed in different ways, such as full load, incremental load, or delta load. Full load involves loading all the data into the target system, while incremental load only loads new or modified data since the last load. Delta load loads changes that have occurred since the last load, making it a faster and more efficient method of loading data.
The above steps are usually automated by ETL jobs. ETL jobs are typically run on a scheduled basis, such as daily, weekly, or monthly, and are used to support a wide range of data integration and analytics tasks. ETL jobs can quickly become complex to manage and resource intensive as the amount of data and requirements for individual transformations rise. Advanced ETL tools such as SAS ETL Studio use load balancing to distribute the workload of data extraction, transformation, and loading across multiple servers or clusters to improve overall performance and efficiency. A load balancer can help prevent overloading of any one server or resource during peak usage, ensuring that the ETL process can continue to operate at optimal levels without being slowed down or interrupted. Cloud load balancing has advanced traffic management capabilities and can be used in an ETL process to distribute the workload across multiple servers and a Cloud CDN ( Content Delivery Network) can be used in the ETL process to improve data transfer performance and availability.
Source: YouTube
Why businesses need reverse ETL
A data warehouse (DWH) is a type of data management system that is designed to enable and support business intelligence (BI) activities, especially analytics. Data warehouses are solely intended to perform queries and analysis and often contain large amounts of historical data. Even though the intent of creating a DWH was to remove data silos, many companies still struggle with the issue of data being siloed in the DWH. Once the data is in the DWH, it is difficult to get make it usable with business tools and as such, data stored in the DWH may not be used effectively. ETLs are rarely used to feed business applications and this where reverse ETL play an important role. Reverse ETL makes DWH data available to business applications.
Data consistency is crucial for businesses as it ensures that all the data across different systems is accurate and up-to-date. Reverse ETL helps in ensuring that data in the operational systems is consistent with the data in the data warehouse or data lake. Reverse ETL also helps in ensuring that data governance policies are followed across different systems. By transferring data from the data warehouse or data lake to operational systems, businesses can enforce data governance policies in real-time.
Operationalize your data
In the context of reverse ETL, operationalizing your data means taking the transformed data and making it available for use in operational systems, such as a customer relationship management (CRM) system, a marketing automation platform, or a data visualization tool. This may involve integrating the data with these systems using APIs or other data integration tools. Customer Data Platforms (CDP) is an off-the-shelf platform that allows you to build a single customer repository by connecting all of the organization’s data sources. CDP offers advanced functionalities such as preparing data for segmentation, creation of aggregates, scores, etc. and making it available to business applications.
Operationalizing your data is an important step in the reverse ETL process, as it allows organizations to derive value from their data by using it to drive real-time decision-making and operational activities.