Introduction
The Argmax function is used widely in building machine learning algorithms: it often serves as the final prediction rule in classification algorithms. In this article, we begin by motivating the need for the argmax function. We then describe the working of the built-in argmax function in Numpy (Python Argmax). The working of the numpy function on both 1 and 2 dimensional arrays will be described, along with code examples.
Table of contents
Also Read: What is Argmax in Machine Learning?
Python Argmax
Argmax stands for Argument of the Maximum. It is a mathematical function that takes as input a function f(x) and returns the points from the domain (argument) of f where the function is maximized. In Python, the argmax function typically operates on arrays, which could be potentially multidimensional. The general idea is that the position of the maximum element is returned by the Argmax functions in Python.

numpy Argmax
Python does not natively support the argmax operation. The Numpy library, on the other hand, has the np.argmax() function that can be used to extract the indices of the maximum elements of Numpy arrays. Consider a 1-dimensional numpy array as shown below.

In this illustrative example, the array elements denote the probability values output by a classifier. The indices of the numpy array are also shown below. The maximum element is 0.613 and it occurs at the index 2. Thus, the argmax function returns the value 2, the index of the maximal element within the array.
Numpy’s argmax function also applies to multi-dimensional arrays. We will illustrate the working with a two-dimensional array as shown below.
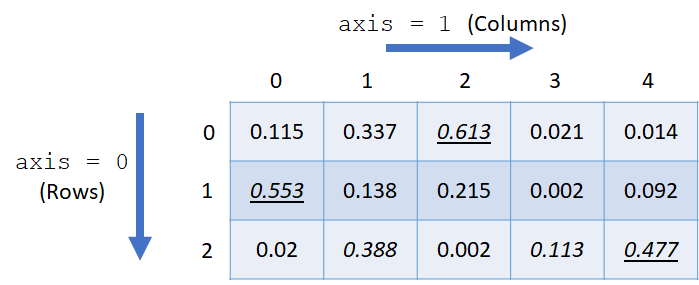
Two-dimensional arrays have two axis for argmax operations: rows and columns. By convention, rows belong to axis 0 and columns belong to axis 1. Each entry of the 2-dimensional array in the figure is a probability value and could represent the output of three classifiers (rows) that solve a 5-class classification problem (columns). Thus, the rows sum up to 1 as each classifier outputs 5 probability values. The maximum element along the rows is underlined, whereas the maximum element along the columns is italicized. Note that the same value may represent the maximal values along both the rows and the columns. For example, the value 0.553 is the maximum element for its row, as well as its column. This results in the value being both underlined and italicized.
The axis parameter of the np.argmax function can be used to specify the axis along which the argmax operation will be performed. We describe the behavior of the axis parameter next, starting with the column-wise option, as it is more intuitive.
Also Read: What is a Sparse Matrix? How is it Used in Machine Learning?
Case 1: Axis param = 1 (columns)
The function will scan through the columns and return the indices of the max values for each row. Thus, a value for each row is returned. In the figure above, we are looking for the underlined entries, resulting in the output of [2, 0, 4].
In the aforementioned interpretation of these values, the array of indices can be interpreted as: “for each model, return the class with the highest probability (prediction)”. In an ensembling strategy, it may be used to vote among several models and predict the class that is the most frequent top-class across the models.
Case 2: Axis param = 0 (rows)
In this case, the function will scan through the rows and return the index of the maximum value for each column. Therefore, one index, the row number, will be returned for each column. In the figure above, we are lookin for the italicized entries, resulting in the output of [1, 2, 0, 2, 2].
In the example above, the array of indices can be interpreted as: “for each of the 5 class, return the model that gives the highest probability to the class”. It may be used for finding biases across several models and other detailed analysis of the results.
If no axis parameter is specified, then the default behavior is to flatten the input tensor and return the argmax of the flattened array. In our example, the flattened array is [0.115, 0.337, 0.613, 0.021, 0.014, 0.553, 0.138, 0.215, 0.002, 0.092, 0.02, 0.388, 0.002, 0.113, 0.477] and its argmax is 2, the index of the maximum element 0.613.
Finally, the np.argmax function also allows the output to be directly inserted to an output array using the out parameter.
Why is Argmax useful
Consider a typical multi-class classification problem, where the machine learning model is tasked with selecting one among 3 classes C1, C2 and C3 for the given input, as illustrated in the figure below. This is a common situation, as many architecture employ a softmax layer in the final layer to compute probability-like values. This array of floats represents the confidence that the model has on each of the classes and can be used as the probability for the classes. In the figure below, a one-dimensional array of 3 probabilities will be produced.
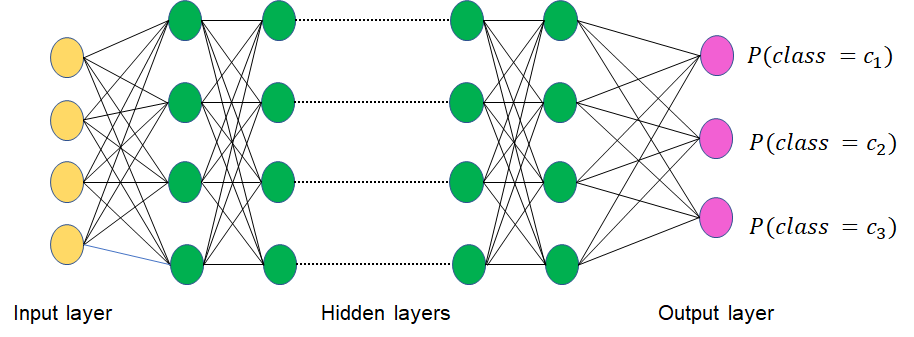
The decision rule is to then assign the class corresponding to the highest probability. The Argmax function is used to then programmatically select the class label based on the probability values. In our case, say the class labels are arranged in the array [‘C1’, ‘C2’, ‘C3’]. Argmax of the probabilities can be used to directly index into this array and return the class label.
Experiment with numpy Argmax
We provide a small example below with the same 2-D input array as above. We begin by initializing this array and computing the argmax along the columns, followed by the rows. We then flatten the 2D array to get a 1D representation. The argmax of the 1D version is shown to be the same as the argmax on the original matrix when no axis parameter is specific.
import numpy as np X = np.array([[0.115, 0.337, 0.613, 0.021, 0.014], # A 2-D input array [0.553, 0.138, 0.215, 0.002, 0.092], [0.020, 0.388, 0.002, 0.113, 0.477]]) print(np.argmax(X, axis = 1)) # Column-wise # Output
[2 0 4] print(np.argmax(X, axis = 0)) # Row-wise # Output
[1 2 0 2 2] print(X.flatten()) # Flatten to get a 1D array # Output
[0.115 0.337 0.613 0.021 0.014 0.553 0.138 0.215 0.002 0.092 0.02 0.388
0.002 0.113 0.477] print(np.argmax(X.flatten())) # argmax of the flattened 1-D array # Output
2 print(np.argmax(X)) # When no axis param is specified, argmax is on the flattened array # Output
2Also Read: Rectified Linear Unit (ReLU): Introduction and Uses in Machine Learning

Conclusion
We reviewed the argmax function, its importance in machine learning and the builtin argmax function in Numpy in Python. The function returns the position of the maximum element in the array and can be used along different axis of a multidimensional array. The argmax function is most commonly used to index into an array of class labels to predict the class based on probabilities computed by the machine learning model.
Reference
Numpy.Argmax — NumPy v1.24 Manual. https://numpy.org/doc/stable/reference/generated/numpy.argmax.html. Accessed 3 Feb. 2023.
“Numpy.Argmax in Python.” GeeksforGeeks, 22 Aug. 2017, https://www.geeksforgeeks.org/numpy-argmax-python/. Accessed 6 Feb. 2023.
Ebner, Joshua. “Numpy Argmax, Explained.” Sharp Sight, Inc, 9 Nov. 2020, https://www.sharpsightlabs.com/blog/numpy-argmax/. Accessed 6 Feb. 2023.